Abstract
Domain generalization의 first learning-based visual odometry
up-to-scale loss function을 제안 - monocular VO의 고질적인 문제인 scale ambiguity를 커버
camera intrinsic parameter를 모델에 포함
Introduction
왜 learning based 모델이 geometry-based method를 이기지 못할까?
기존 learning based method들은
1) data의 diversity에 약해서 이다.
2) well-formulated geometry knowledge를 무시해서이다.
Introduction
<Main contribution>
1) data diversity on the generalization ability of VO model이 왜 중요한지 실험적으로 보여줬다.
2) up-to-scale loss 제안
3) Intrinsics Layer (IL)을 제안하여 다른 카메라에 대해서 generalization할 수 있는 모델
Method
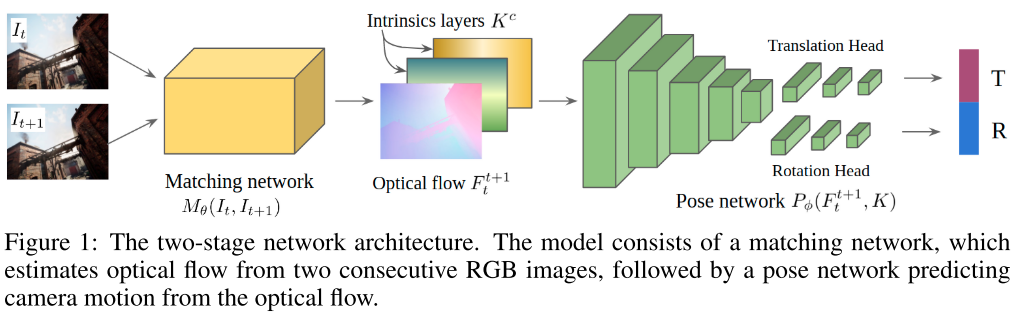
Training on large scale diverse data
* diverse scene과 motion pattern이 담겨있는 Tartan Air dataset을 쓰겠다.
* end-to-end loss function
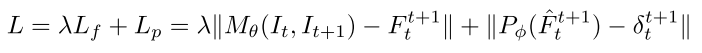
Up-to-scale loss function
* KITTI dataset과 같은 경우에는 카메라의 height가 고정되어 있기 때문에, 만약에 조금이라도 바뀐다면, 동작을 잘 못하게된다.
* scale ambiguity를 바로 잡기 위하여 R값에 constraint를 걸어준다.
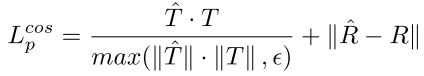
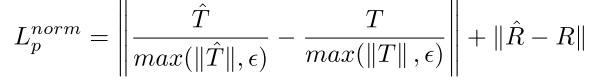
Cross-camera generalization by encoding camera intrinsics
* Visual geometry 방법에서는 Essential matrix를 구하기 위해 camera intrinsic 정보가 필요하다.
* 기존 방법에서는 camera가 바뀌는 상황에 대한 generalization을 고려하지 않았다.
* camera가 기본적으로 가지고 있는 resolution 및 Field of View를 맞춰주는 작업
Intrinsic layer
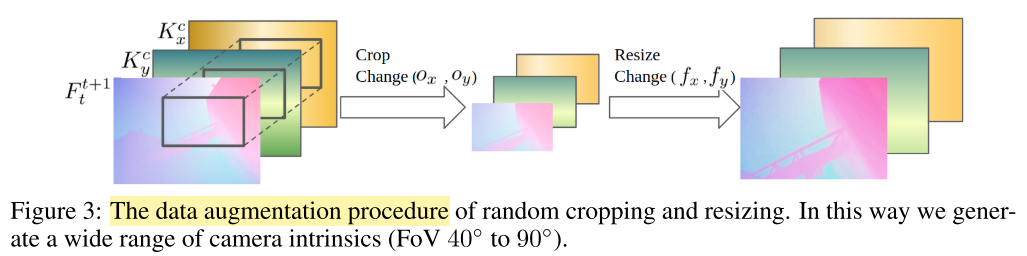
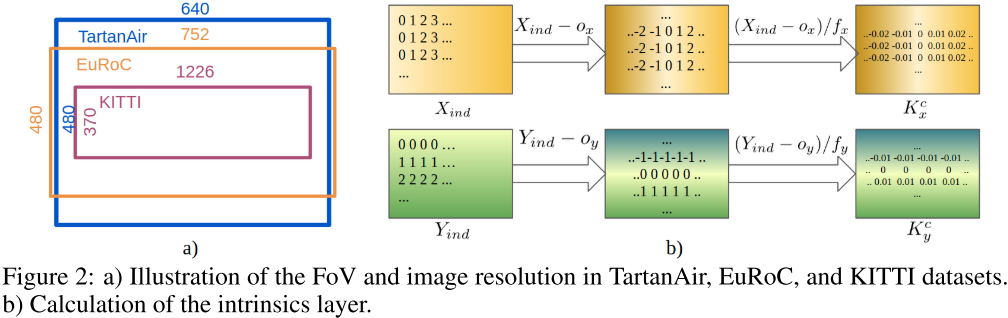
Data generation for various camera intrinsics
* TartanAir 는 오직 하나의 f_x = f_y = 320, o_x =320, o_y = 240의 intrinsic을 가지고 있다.
* 하지만 우리 method를 적용해봤을 때, generalization performance가 improved되더라



